이번 시간에는 앙상블 기법 중 부스팅에 대하여 다뤄보도록 하겠습니다.
해당 내용은 '파이썬 머신러닝 완벽 가이드'를 정리한 내용입니다.
1. 부스팅 알고리즘
부스팅 알고리즘 : 여러 개의 약한 학습기(weak learner)를 순차적으로 학습-예측하면서 잘못 예측한 데이터에 가중치 부여를 통해 오류를 개선해 나가면서 학습하는 방법
2. 에이다 부스트(AdaBoost)
에이다 부스트 : 오류 데이터에 가중치를 부여하면서 부스팅을 수행하는 알고리즘

위의 사진을 보면서 에이다 부스트의 수행 방법을 살펴보겠습니다.
1. 첫 번째 약한 학습기를 통해 분류
2. 오류 데이터에 대하여 가중치 부여
3. 다음 약한 학습기를 통해 분류
4. 위 과정을 반복 후 각 분류 기준에 대하여 가중치를 부여하여 결합하여 예측 수행
3. GBM(Gradient Boost Machine) 및 구현
GBM : 에이다부스트와 수행 방법은 유사하나 가중치 업데이트 시 경사 하강법(Gradient Descent)을 사용하는 것이 큰 차이입니다.
(경사하강법에 대해서는 회귀에서 더욱 상세하게 다루도록 하겠습니다.)
GBM은 GradientBoostingClassifier API를 통해 구현이 가능합니다.
주요 파라미터
loss : 경사 하강법에 사용할 비용 함수
learning_rate : GBM에 적용할 학습률, 학습률이 너무 작으면 최소 오류 값에 도달하기 이전에 학습이 종류 될 가능성이 있고 학습률이 너무
크면 최소 오류값을 지나칠 가능성이 있기 때문에 적절한 학습률을 찾는 것이 매우 중요합니다.
n_estimators : weak learner의 개수, 개수가 많아지면 일정 수준까지 좋아질 수 있으나, 수행 시간이 오래 걸림
subsample : weak learner 학습에 사용하는 데이터의 샘플링 비율
GBM을 통해 사용자 행동 데이터 세트를 예측해보도록 하겠습니다. GBM과 같은 부스팅 방법은 하이퍼 파라미터 등 세팅이 더욱 복잡하고 랜덤 포레스트와 비교하여 수행 시간이 오래 걸립니다. 수행 시간도 같이 확인해보도록 하겠습니다.
from sklearn.ensemble import GradientBoostingClassifier
import time
import warnings
warnings.filterwarnings('ignore')
X_train, X_test, y_train, y_test = get_human_dataset()
# GBM 수행 시간 측정을 위함. 시작 시간 설정.
start_time = time.time()
gb_clf = GradientBoostingClassifier(random_state=0)
gb_clf.fit(X_train , y_train)
gb_pred = gb_clf.predict(X_test)
gb_accuracy = accuracy_score(y_test, gb_pred)
print('GBM 정확도: {0:.4f}'.format(gb_accuracy))
print("GBM 수행 시간: {0:.1f} 초 ".format(time.time() - start_time))
GBM 정확도: 0.9386
GBM 수행 시간: 191.9 초실행 결과를 보면 93%로 랜덤 포레스트로 수행했을 때와 비교했을 때 성능이 더욱 우수함을 알 수 있습니다. 하지만 3분 이상의 시간이 소요됐네요...
이제 하이퍼 파라미터를 수정하여 성능을 향상해보도록 하겠습니다.
from sklearn.model_selection import GridSearchCV
params = {
'n_estimators':[100, 500],
'learning_rate' : [ 0.05, 0.1]
}
grid_cv = GridSearchCV(gb_clf , param_grid=params , cv=2 ,verbose=1)
grid_cv.fit(X_train , y_train)
print('최적 하이퍼 파라미터:\n', grid_cv.best_params_)
print('최고 예측 정확도: {0:.4f}'.format(grid_cv.best_score_))
Fitting 2 folds for each of 4 candidates, totalling 8 fits
최적 하이퍼 파라미터:
{'learning_rate': 0.1, 'n_estimators': 500}
최고 예측 정확도: 0.9008
# GridSearchCV를 이용하여 최적으로 학습된 estimator로 predict 수행.
gb_pred = grid_cv.best_estimator_.predict(X_test)
gb_accuracy = accuracy_score(y_test, gb_pred)
print('GBM 정확도: {0:.4f}'.format(gb_accuracy))
GBM 정확도: 0.9420최종 GBM 정확도가 94%로 향상되었습니다. 근데 학습하는데 정말 오래 걸리네요...ㅎㅎ
4. XGBoost
XGboost는 트리 기반 앙상블 기법에서 매우 각광받는 방법으로 일반적으로 다른 머신러닝 알고리즘에 비해 큰 차이는 아니지만 우수한 성능을 가집니다. XGboost의 장점은 다음과 같습니다.
- 뛰어난 예측 성능 : 일반적으로 뛰어난 예측 성능을 보임
- GBM 대비 빠른 수행 시간
- 과적합 규제 : XGboost 자체에 과적합 규제 기능
- Tree pruning : 더 이상 이득이 없는 분할을 가지치기하여 분할 수를 더 줄여줌
- 자체 내장된 교차 검증 : 자체에 교차 검증을 할 수 있음. 또한 조기 중단 기능이 있다.
- 결손 값 자체 처리
XGboost는 파이썬 래퍼 XGboost와 사이킷런 기반 XGboost가 있습니다. 어떤걸 기반으로 하냐에 따라 하이퍼파라미터가 달라지는 복잡성이 있습니다. 따라서 앞으로 사이킷런 기반 XGboost를 사용할 예정이기 때문에 이에 대한 파라미터만 다루도록 하겠습니다. 부스팅 기반 앙상블 기법은 하이퍼 파라미터의 종류가 매우 다양하기 때문에 그때그때 참조하는 게 좋을 것 같습니다!!
주요 부스터 파라미터
n_estimators : 반복을 수행할 횟수
learning_rate : 학습률을 결정
num_boost_rounds : 약한 학습기의 개수
min_child_weight [default=1] : 트리에서 가지를 추가적으로 나눌지 결정하기 위해 weight의 총합. min_child_weight가 클수록 분할을 자제
min_split_loss : 리프 노드를 추가적으로 나눌지 결정하는 최소 손실 값. 손실 값이 해당 값보다 클 경우 리프 노드 분할
max_depth [default=6] : 트리의 최대 깊이
sub_sample [default=1] : 트리를 생성하는 데 사용되는 데이터의 비율
colsample_bytree [default=1] : 트리 생성에 필요한 피처의 개수.
reg_lambda : L1 Regularization 적용 값
reg_alpha : L1 Regularizaion 적용 값
scale_pos_weight [default=1] : 불균형한 데이터 세트의 균형을 유지하기 위한 파라미터
early_stopping_rounds : 해당 횟수 이상으로 손실 값이 나아지지 않는다면 조기 종료.
XGboost를 사용한 실습은 아래 포스트를 참고하시면 됩니다.
5. LightGBM
LigthGBM은 XGboost와 함께 매우 각광받는 부스팅 기법입니다. XGboost에 비해 학습 시간과 메모리가 적게 사용된다는 장점이 있습니다. 또한 CPU 병렬 사용뿐만 아니라 GPU도 지원하고 있습니다. 한 가지 단점으로는 10000건 이하의 데이터에 대해서는 과적합이 발생하기 쉽다고 합니다. LightGBM은 일반적인 GBM계열과 달리 리프 중심 트리 분할을 사용합니다. 일반적인 GBM 계열은 오버 피팅에 더 강한 구조를 위해 균형 트리를 사용하지만 이는 시간이 오래 걸린다는 단점이 있습니다. 따라서 LightGBM은 최대 손실 값을 가지는 리프 노드를 계속해서 분할하여 예측 오류 손실을 최소화하고 있습니다.
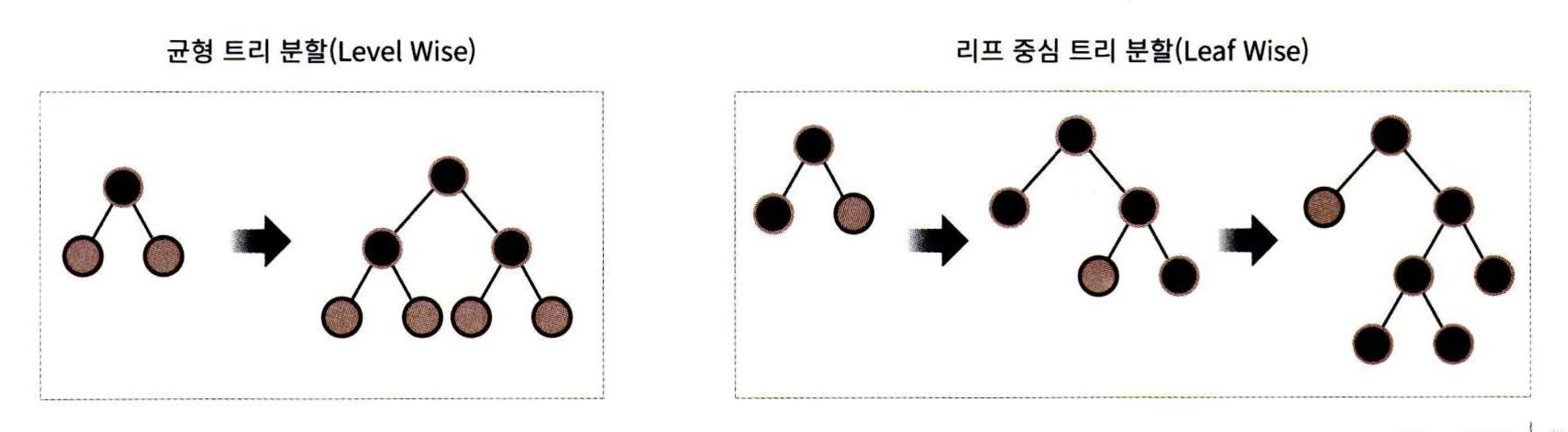
또한 LightGBM은 카테고리형 피처의 자동 변환과 최적 분할을 지원하기 때문에 원-핫 인코딩 등을 사용하지 않고도 카테고리형 피처를 자동 변환합니다.
실습은 아래 포스트를 참고하시면 됩니다. 주요 파라미터는 XGboost와 동일하기 때문에 위의 주요 파라미터 설명을 참고하시면 됩니다.
이상으로 앙상블 기법의 하이라이트인 부스트 기법에 대한
정리를 마치도록 하겠습니다. 부스팅 기법은 캐글 등에서 매우 자주 사용됩니다.
또한 파라미터 수가 복잡하기 때문에 필요한 파라미터는
그때그때 찾아서 사용하면 될 것 같습니다.
긴 글 읽어주셔서 감사합니다 ㅎㅎ

'파이썬 머신러닝 완벽가이드' 카테고리의 다른 글
| 4.5 LightGBM 실습 (0) | 2022.01.02 |
|---|---|
| 4.5 XGboost 실습 (0) | 2022.01.02 |
| 4.4 앙상블 학습(배깅) (0) | 2021.11.23 |
| 4.3 앙상블 학습(보팅) (0) | 2021.11.23 |
| 4.2 결정 트리 실습 - 사용자 행동 인식 데이터 세트 (0) | 2021.11.22 |



