이번 시간부터 이제 본격적으로
머신러닝 분류의 하이라이트 앙상블에 대하여 다뤄보도록 하겠습니다.
앙상블 학습 유형에 따라 이론과 실습을 진행하도록 하겠습니다.
해당 내용은 '파이썬 머신러닝 완벽 가이드'를 정리한 내용입니다.
1. 앙상블 학습(Ensemble Learning)
앙상블 학습 : 여러 개의 분류기를 생성하고 그 예측을 결합함으로써 보다 정확한 최종 예측을 도출하는 기법으로,
크게 보팅(Voting), 배깅(Bagging), 부스팅(Boosting)으로 나눌 수 있다.
앙상블은 단순하게 생각해서 여러 명의 전문가가 모여 다같이 힘을 합쳐 문제를 해결하는 것이라 생각하면 됩니다. 앙상블 기법을 통해 대부분의 정형 데이터 분류 시 높은 성능을 보여줍니다.
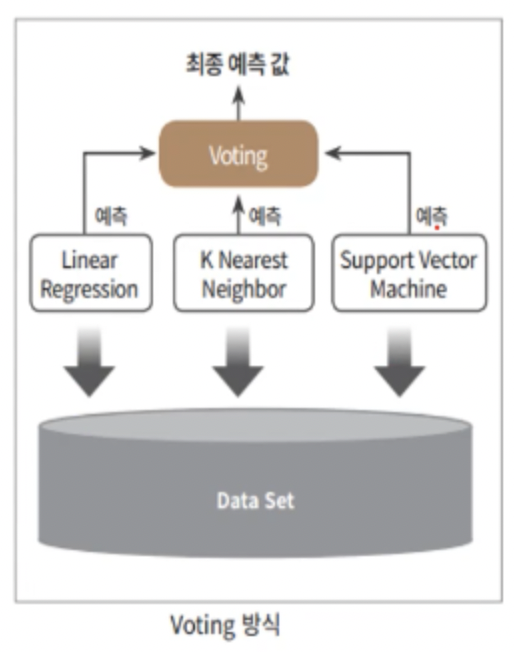
2. 보팅(Voting)
보팅(Voting) : 서로 다른 알고리즘을 가진 분류기를 결합하여 최종 예측 값을 구하는 방법
보팅 유형으로는 하드 보팅과 소프트 보팅이 있다.
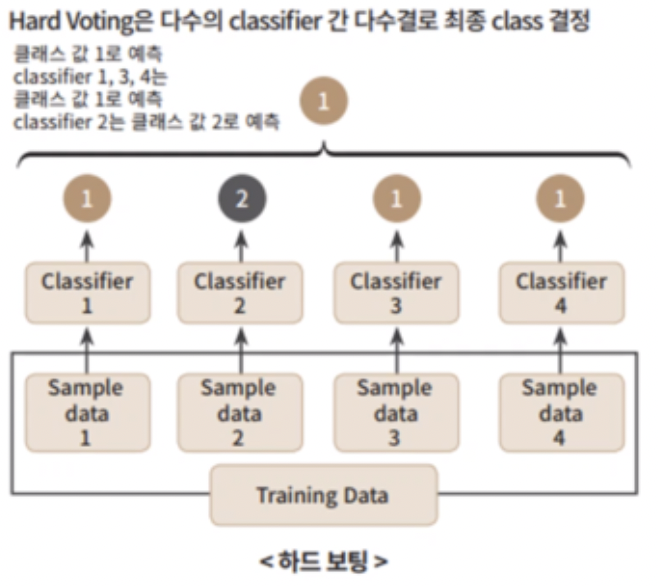
2.1 하드 보팅(Hard Voting)
하드 보팅 : 개별 분류기가 각자의 레이블값을 도출하면 그중 가장 많은 표를 얻은 레이블이 최종 레이블로 결정되는 방식
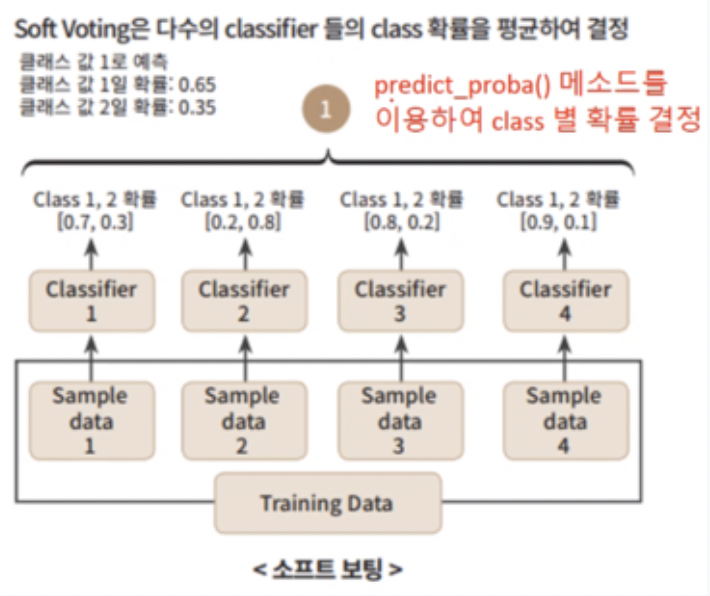
2.2 소프트 보팅(Soft Voting)
소프트 보팅 : 개별 분류기가 레이블별 확률을 구한 후 구해진 확률의 평균을 구하여 평균값이 더 높은 레이블이 최종 레이블로 결정되는 방식
일반적으로 소프트 보팅의 성능이 더 우수함
3. 보팅 분류기 실습
보팅 방식의 앙상블은 사이킷런의 VotingClassifier API를 통해 구현이 가능합니다.
사이킷런의 자체 위스콘신 유방암 데이터 세트를 보팅 분류기로 예측해보도록 하겠습니다.
import pandas as pd
from sklearn.ensemble import VotingClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 위스콘신 유방암 데이터 세트
cancer = load_breast_cancer()
data_df = pd.DataFrame(cancer.data, columns=cancer.feature_names)
로지스틱 회귀와 knn을 소프트 보팅 방식으로 결합한 앙상블 모델의 예측 성능과 개별 모델의 예측 성능을 비교해보도록 하겠습니다.
# 개별 모델은 로지스틱 회귀와 KNN 임.
lr_clf = LogisticRegression()
knn_clf = KNeighborsClassifier(n_neighbors=8)
# 개별 모델을 소프트 보팅 기반의 앙상블 모델로 구현한 분류기
vo_clf = VotingClassifier( estimators=[('LR',lr_clf),('KNN',knn_clf)] , voting='soft' )
X_train, X_test, y_train, y_test = train_test_split(cancer.data, cancer.target,
test_size=0.2 , random_state= 156)
# VotingClassifier 학습/예측/평가.
vo_clf.fit(X_train , y_train)
pred = vo_clf.predict(X_test)
print('Voting 분류기 정확도: {0:.4f}'.format(accuracy_score(y_test , pred)))
# 개별 모델의 학습/예측/평가.
classifiers = [lr_clf, knn_clf]
for classifier in classifiers:
classifier.fit(X_train , y_train)
pred = classifier.predict(X_test)
class_name= classifier.__class__.__name__
print('{0} 정확도: {1:.4f}'.format(class_name, accuracy_score(y_test , pred)))
Voting 분류기 정확도: 0.9474
LogisticRegression 정확도: 0.9386
KNeighborsClassifier 정확도: 0.9386예측 결과를 보면 보팅 분류기의 정확도가 개별 분류기보다 높은 것을 확인할 수 있습니다. 물론 앙상블 학습이 개별 학습보다 항상 높은 성능을 보이는 것은 아닙니다. 하지만 다양한 관점에서 문제에 접근하고 서로의 약점을 보완해서 높은 유연성을 가질 수 있습니다. 높은 유연성은 머신러닝의 중요한 평가 지표이기도 합니다.
이렇게 앙상블의 첫번째 방법 '보팅'에 대하여 정리해봤습니다.
다음 시간은 배깅과 배깅의 대표적인 알고리즘인 랜덤 포레스트에 대하여
학습해보도록 하겠습니다.

'파이썬 머신러닝 완벽가이드' 카테고리의 다른 글
| 4.5 앙상블(부스팅) (0) | 2022.01.02 |
|---|---|
| 4.4 앙상블 학습(배깅) (0) | 2021.11.23 |
| 4.2 결정 트리 실습 - 사용자 행동 인식 데이터 세트 (0) | 2021.11.22 |
| 4.1 분류(결정트리) (0) | 2021.11.22 |
| 3.3 피마 인디언 당뇨병 예측 (0) | 2021.11.22 |



